Hi all – we’ve switched to our new blog URL at :
This site will be closed in a few days
Hi all – we’ve switched to our new blog URL at :
This site will be closed in a few days
 Leave a Comment » |
Leave a Comment » |  Uncategorized |
Uncategorized |  Permalink
Permalink
 Posted by mhookey
Posted by mhookey
![]()
Matteo Rizzi, Innovation Manager, Innotribe, says “I’m delighted to announce DemystData as a semi-finalist and look forward to discovering more about the business. This year’s semi-finalists have assessed the developments and trends in the region and have identified opportunities in the market. The entrants have each demonstrated a forward-thinking and innovative approach to the financial sector and have developed start-up businesses which could have profound impacts on the future of the industry. I’m extremely excited to give DemystData the opportunity to pitch its ideas to some of the top decision makers in the industry”.
Enough said! Looking forward to seeing everyone in Singapore on April 24th,
About Innotribe
Launched in 2009, Innotribe is SWIFT’s initiative to enable collaborative innovation in financial services. Innotribe presents an energising mix of education, new perspectives, collaboration, facilitation and incubation to professionals and entrepreneurs who are willing to drive change within their industry. It fosters creative thinking in financial services, through debating the options (at Innotribe events) and supporting the creation of innovative new solutions (through the Incubator, Startup Challenge and Proof of Concepts (POCs). It is through this approach, the Innotribe team at SWIFT is able to generate a platform that enables innovation across SWIFT and the financial community. For more information, please visit http://www.innotribe.com/.
Leave a Comment » | Uncategorized | Tagged: demyst data, innotribe startup challenge, predictive analytics, social data, SWIFT | Permalink
Posted by kjdenberg
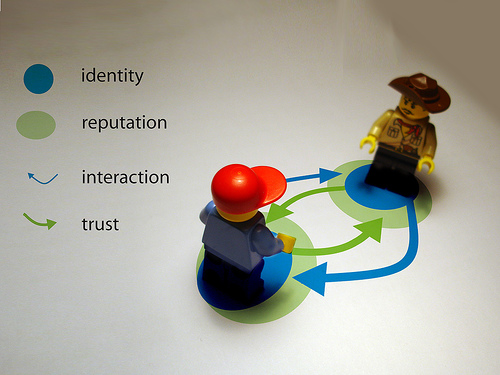
If you’ve ever read our blog or navigated our site, you’ve likely seen the phrase, ‘removing information asymmetries’. If you’ve sat through a meeting with us, you’ve been lectured on how data transparency can benefit the consumer. Let me try to connect the dots.
Asymmetric information refers to a situation in which one party in a transaction has more or superior information compared to another. Economist George Akerloff publicized the problems of asymmetric information in his 1970’s paper discussing the ‘market for lemons’ in the used car industry. He explained that because a buyer cannot generally ascertain the value of a vehicle accurately, he/she would be willing to pay only an average price for it. Knowing in advance that the ‘good sellers’ are going to reject this average price, the buyer removes the aforementioned ‘lemon seller’s advantage’ by adjusting downward the price they are willing to pay. In the end, the average price isn’t even offered, only the ‘lemon’ price is. Effectively, the ‘bad’ drive the ‘good’ out of the market.

A similar situation occurs in the credit markets. Let us examine a case in which a lender is faced with uncertainty about the creditworthiness of a group of borrowers. Having to account for the bad risks, lenders are pushed to charge artificially high interest rates to cross subsidize their risk. Recognizing this and not willing to borrow at usurious rates, the good subset of creditworthy borrowers remove themselves from the credit markets. Similar to above, the ‘bad’ have driven out the ‘good.’
This inefficient risk cross subsidization affects a large portion of the $many trillion financial services markets, and removing it will yield huge value in the coming years. The availability of information is paramount to realizing this value. Fortunately, data today is being created at an unprecedented rate.
At Demyst.Data, we are constructing the infrastructure and mechanisms to aggregate & analyze this data. Our clients are working to engage the consumer to share their information and educating them on the benefits of transparency. Together, we are removing the asymmetries necessary to draw the ‘goods’ back to the market and to help lenders make educated lending decisions. We believe we’re engaged in a win/win game; hence, our passion, excitement, and enthusiasm about the potential value of improved information.
Leave a Comment » | Uncategorized | Tagged: demyst data, george akerloff, information asymmetry, market for lemons | Permalink
Posted by kjdenberg
As we’ve added hundreds of interesting online attributes, we’ve been hitting some performance bottlenecks when processing larger, batch datasets. This hasn’t been an issue for customers thankfully, and it doesn’t affect our realtime APIs, but it’s still frustrating. I had a spare day, so it felt like time for a performance boost.
Here’s the executive summary :
To start I spun up a deliberately small cut down test server, set up a reasonably complex API, and used the great tools at http://blitz.io to rush the API with hundreds of concurrent requests

That spike at the start was a concern, even though it is on a small server.
All the CPU usage was in rack/passenger, so I dusted off the profiler. Thread contention was getting in the way. We need threads because we integrate with so many third party APIs. We were still on REE for it’s memory management, however that uses green threads, so it was time to bite the bullet and (1) update to ruby 1.9.X.

That helped a fair amount, but we were still getting the timeouts.
So we re-ran the profile and noticed a strange amount of time in activerecord associations and one particular activerecord and a different mongodb query. This led to a few things …
2. We didn’t dig in to why but mymodel.relatedmodel.create :param => X was causing some painful slowness in the association code. It wasn’t that important to keep the syntactic sugar; switching to Relatedmodel.create :mymodel_id => mymodel.id, :param => X saved a bunch.
3. We added a couple of activerecord indexes, which helped a bit. MongoDB indexes were working a charm, but there was one particular group of 3 independent indexes that were always used in conjunction, and the mongo profiler was revealing nscanned of >10000 for some queries. Creating a combined index helped a lot. Another couple of examples that remind us that, while ORMs are nice, you can never forget there’s a database sitting under all of this.
The result?

And no timeouts until about 150 concurrent hits.
The performance was already plenty in our production system (we automatically scale horizontally as needed), but this helped improved things about 2-3x.
That’s enough for today. We’ll share some more details on performance benchmarks in the coming weeks.
Any other thoughts from the community? Please email me (mhookey at demystdata dot com).
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
Facebook’s documentation on authentication via Facebook and the graph API is very comprehensive … but sometimes a worked example still helps. Here is how you can add a “Connect with Facebook” button with minimal effort, using rails, coffeescript, and ruby
You need to register your app with Facebook if you haven’t already
From here. Look under authentication, and copy/paste to application.js and/or /layouts/application.html.erb. Add this line to the script to make sure the async loading works
window.setup();
<div class="field">; <fb:login-button size="large"> Connect to Facebook </fb:login-button> </div>
For example if you want to access the logged in customer’s profile after they have logged in, to customize the page, you might do something like this in coffeescript:
$ ->
window.setup()
window.setup = ->
window.FB.Event.subscribe('auth.login', -> do_something()) if window.FB?
do_something = ->
console.log "doing something ..."
window.FB.getLoginStatus (authtoken) ->
if authtoken.authResponse
window.FB.api '/me', (fbdata) ->
console.log "FB name : #{fbdata['name']}"}
# Add interesting personalization logic here
… and you’re ready to go
We have a white labelled offering where we can host this for you, and return the data through painless APIs, in case you’re looking to get up and running even faster. email us and let us know what you’re working on.
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
The simplest starting point for any user is the basic Aggregation API, where you can pull together all of the best customer data based on minimal inputs. This is for the more advanced users that want to build their own analytics.
Are you looking for Yahoo or Google data? Geolocation data? Or demographics by email? This Aggregation API may be a great way to start.
This was always available, but we’ve now given it the pride of place that it deserves and a permanent, static endpoint (/engine/raw).

Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
Something we’re proud of here at Demyst.Data is the ability to create APIs based on minimal input variables. The most common use case we come across is offer targeting. In short this means that you can guide your visiting customers towards the most relevant products, by predicting something (such as conversion likelihood) based solely on their IP
To learn more, see our ‘how-to’ : https://beta.demystdata.com/info/use_offer

Leave a Comment » | Uncategorized | Permalink
Posted by mhookey

Based on client requests, we’ve been hard at work tapping in to additional useful variables. A quick update on highlighted additions :
We’re always open to special requests, so please let us know if you have an upcoming project that requires integrating with better web data, segmentation, or predictive analytics but haven’t quite figured out how to apply the demyst.data toolkit.
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
We’re pleased to announce the release of what-if (scenario testing) functionality for each API, all included within the base package.
This allows you to perform scenario testing on your underlying API. For example if you build a conversion API, where product offered is a variable, it can be nice to test the impact of changes to product offers. This is now possible :

Be warned though, if you want to draw strong conclusions from this analysis you’re predicting a counterfactual scenario. To do that with the most confidence, statistical purists would strongly suggest you need a randomized experiment (in this case random in the product offer variable). Even if you don’t have this, our modeling approach bring in as much third party data as possible to remove the biases inherent in an historical analysis, as such it can still suggest where the low hanging fruit might be.
Try it out, under ‘what-if’ on the left hand side.
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
In our continued effort to demystify data, we’ve recently published our available attributes, which clarifies which inputs are required for each attribute. We’re continually updating this list, so please let us know if you have any suggested additions.

Occasionally it can be nice to avoid using (or even seeing) particular attributes. We’ve recently added support for this too … within the Account page. Just enter a comma separated list of values, and when third party data is being appended, any fields with names including this text will be skipped.

If you have any questions or suggestions, please let us know.
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
We all want to ask as few questions as possible on our web forms. However each question adds incremental value. How do we think through the trade-off of additional questions (leading to accuracy) vs simplicity?
First, let’s illustrate the tradeoff here.

We’re trying to find the optimal number of questions, where conversion is maximized, subject to some minimum level of information content.
The first, perhaps obvious, observation here, is that third party data is always a good idea. You get extra information content, for example to customize offers and look and feel, without impacting on the consumer experience.
Next, we need some way to test the information content of various subsets of the questions. Demyst.Data offers a way to do this – but the concept is pretty simple.
1. Upload your exhaustive questions, and a target variable

2. Fit some scorecard or segmentation that you’re happy with
Here’s ours. This can be thought of as the ‘taj mahal’ workflow (i.e. all questions are included).

3. Delete columns, rinse and repeat
The next step is to delete each column, and refit the entire scorecard, and plot side by side. Again, here’s one we prepared earlier.

The orange line, the baseline, is flat (clearly if you don’t ask any questions then predictive lift isn’t possible). The red line is what it looks like if no “Demyst” data is appended. All this means is we’ve temporary turned off the third party data and refit. The “without demyst” line is almost as steep as the full ‘taj mahal’ line. In a real dataset, this might mean you wouldn’t bother buying third party data (not something we’d advocate – actually what’s happening here is the emails are always joe, or john, so it’s not surprising that it’s not adding much value).
4. Keep going
There’s a near limitless number of permutations of this exercise.

No we can see that credit and email as standalone don’t add much value. Age is really the winner here, suggesting a radically simpler quoting process.

We don’t have the full picture yet, since we don’t know if that reduction in lift is compensated by a corresponding lift in conversion thanks to a simpler workflow. That’s a topic for another post.
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
Thank you to all who have registered for a private beta trial. We’re thrilled with number of requests and will continue to open up spots daily. For those of you who have already signed up and tested the tool, please, don’t be shy, send us your reactions. We need real user feedback so we can perfect the experience and continue to meet our clients needs better.
In line with some of the input from early adapters, we’re excited to announce a new addition to our team, Bryan Connor, a UX and data visualization expert who is putting in countless hours to make the product as user friendly and intuitive as possible. You can sample some of Bryan’s prior work at http://dribbble.com/bryanconnor and I’ve included an initial iteration of the tool below (or, sign up here for a beta trial- the new design is in place!).

In other updates, our engineers continue to enhance the modeling techniques, access new data sources, and perfect the outputs to improve on some of the results of our early pilots. And of course, we’re working on our 7-minute demo for Finovate and getting our travel plans in place. Hit us up, we’re seeing up to 40% lift in predicting default versus the status quo. Let us help you grow!
Comments Off on Beta invites, UX, & stuff | Uncategorized | Tagged: beta invites, Finovate, UX | Permalink
Posted by kjdenberg

“We’re really excited to have DeMyst Data demoing their innovative new solution at FinovateFall. We think the audience will find their new solution for helping lenders with segmentation and offer customization via alternative data sources very interesting.” ~Eric Mattson, CEO of Finovate
For those of you unfamiliar with Finovate, it is “the conference” for showcasing innovations in the fields of banking and financial technology. On stage, we’ll publicly launch the tool and demo some of our initial results with real client data. Our focus will be on exposing lenders to the rich segmentation we are able to create with minimal customer inputs and illustrating how the outputs can be used to customize offers for thin file consumers.
We’ll be in NY (and traveling around the US) for a few weeks leading up to the conference and look forward to re-connecting with many of you and meeting others for the first time. Drop us a note, we’d love to share some results and discuss how the product can help you grow!
Leave a Comment » | Uncategorized | Tagged: alternative data, Finovate, offer customization, sementation | Permalink
Posted by kjdenberg

It was Mark Twain who popularised it, but the original authorship of the oft quoted phrase “lies, damn lies and statistics” is widely contested. One to whom it is frequently attributed is Benjamin Disraeli. A distinguished conservative politician and literary figure, Disraeli’s business ventures are deservedly less celebrated.
His speculative investments in South American mining companies in the early nineteenth century proved calamitous and almost ruined him. One wonders whether, had he a more considered view of the power of information than is implied by the phrase with which he is sometimes associated, he may have avoided the pitfalls of reckless investment.
While the world, and particularly the ethereal world, is awash with data (and indeed statistics), it is alarming how infrequently that data is converted to useful information. At a time when data is generated and captured at an unprecedented rate and indeed has become inordinately accessible, it is ironic that we remain so beholden to the spinmeisters and their political masters. The power of information has never been more readily, tantalisingly, at our fingertips but somehow we don’t reach out and grasp it.
At Silne we have a healthy disregard for what we call information asymmetries. In equity markets information asymmetries are said to be removed through the trading activities of arbitrageurs. When I trade on the basis of closely held information I essentially expose that information to the world. In the meantime of course, I make money. Information asymmetries then confer power on the holder of information, or serve to diminish the interests of those without access to it. That’s not fair and we don’t like it.
We define information asymmetries rather broadly … information is available but is not being used; you have information but I don’t; information exists but I don’t know it does. Finding relevant, predictive data, sifting and analysing it, and using it to solve problems and improve decision making is not easy but it can be a route to the truth, not the damn lies which Disraeli so lamented.
Leave a Comment » | Uncategorized | Permalink
Posted by uhajhe
In Rails, it’s all too easy to forget that rails activerecord models sit on top of a database. Don’t.
We tackle big data problems, and queries are usually the performance bottleneck. Here are a couple of simple tips for optimizing rails code without resorting to custom SQL (apologies if some of these seem too obvious to mention, but they can be quite common issues when tackling thousands of records) :
These types of activities can retain the syntactical sugar of rails, which helps with maintenance, readability, and security. It also leads to less overhead when switching backend databases. Finally it’s more fun.
That said, here at Silne we’re crunching some large data on the backend, so there are times when activerecord just won’t cut it, and you need to optimize your data manipulations directly… but don’t discount the flexibility of activerecord.
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
A few weeks ago, Google made its foray into financial services with Google Advisor. The site, in essence a price comparison engine, bills itself as one-stop shop for financial services designed to help users easily find relevant products from multiple providers, compare them side by side, and apply online. Available only in the US, Advisor allows users to create customized searches for products including mortgages, credit cards, CD’s, checking, and savings accounts. The site then, typically within 2 seconds, produces a list of offers that match the user’s criteria along with lender contact info and rates. Finally, Google is only paid when users contact lenders for mortgages. In all other products, Google’s listings are sorted exclusively by APY.

This new domain, which within its first few weeks has solidified top placement in search and garnered 75k YouTube views of it’s “how too” video has left many people scratching their heads asking, “Why?” A couple of thoughts on that:
1- According to their blog, Google had already constructed and begun testing a mortgage comparison tool in 2009 and therefore, adding other financial offers to this product was relatively easy.
2- 5 days after the launch of Advisor, Google announced the acquisition of Sparkbuy, a consumer comparison site, and that Sparkbuy’s 3 person team was joining Google as employees working on the Advisor product, e.g. the perfect operating team.
But rather than ponder “why”, because frankly, I think the answer is, “because they can,” I found myself navigating the site trying to determine “who”, in today’s economy, finds a site like this useful? Practically speaking, the only measure of creditworthiness on the site is self entered, the rates are variable and for comparison only, and the end result of your “customized search” is still an application away from an offer of credit. So, for those of us with a 780 FICO score and the entire spectrum of credit products to choose from, I guess yes, Advisor could be considered a good source of information. But what about for the other 80% of the US population? Think for a second about an average US consumer who is searching for a loan. Their intent is unambiguous- cash or access to credit as quickly as possible at the lowest available interest rate. Through this lens, Advisor’s process of choose the loan that’s “right for you,” browse offers, contact the advertiser, apply, and then get accepted or rejected seems to me to miss the mark.
Now of course, a workflow that facilitates actual lending is much more complex than a comparison tool, which in fairness, Advisor only claims to be. But if anyone, Google has the brand and resources to meet user objectives. Surely, they know enough about each of us to head down the necessary path of individualized customized product offerings, yet, have chosen to shy away. I’ll go out on a limb and predict that Advisor’s intent is not to send free, non-biased referrals to lenders forever, and that in all likelihood, what we are seeing today is only a first iteration. Thoughts?
Leave a Comment » | Uncategorized | Tagged: alternative data, credit cards, credit score, creditworthiness, DeMyst, google advisor, interest rates, Lower interest rate, mortgages, Silne | Permalink
Posted by kjdenberg
Today’s economist chart : http://www.economist.com/blogs/dailychart/2010/12/house_prices
This shows the widely quoted case shiller index.
As always applying the data lens to this : there is some significant risk of bias here. My understanding of the index is they look at value weighted percent changes in registered houses from period to period within each of a basket of representative cities.
That misses a couple of things :
1. New homes
2. Added value of renovations (although I recall reading they seek to remove those from the sample)
3. Inter and intra city mix shifts
With so much riding on home prices, there are more options out there … such as http://radarlogic.com/ … however just like with credit scores (with FICO) there is a widely understood although perhaps inaccurate norm that is quoted in the popular media that seems to serve as the benchmark for most decision makers.
With vertical disintermediation (such as secondary markets for mortgage backed securities) it seems there is even more of a tendency to rely on summary metrics – perhaps this is just practicality. Economists talk of vertical integration being caused by, among other things, very high cost of contracting. In secondary credit markets this seems to exist – e.g. there are contract terms around mortgage prepayment risk and securities tranched by average FICO. I’m not sure if they have terms related to widely used indices like case shiller – but it wouldn’t surprise me. Accounting for the inaccuracies in these measures counts as a high cost of contracting. In fact since data is a competitive advantage for the security originator, it might even be a case of the paradox of information (you can’t contract for it without giving away the ‘secret sauce’).
With these considerations being only exacerbated by increasing data sources, are we going to see the most profitable US banks – heaven forbid – staying veritically integrated, and even securitizing less than they otherwise would?
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
There are already too many posts on this, and it’s completely unrelated to Silne’s focus, but I can’t help but think about the economics of facebook’s new messaging (“don’t call it email!”) offering.
First let me say that it seems cool for some use cases. I.e. maintaining a log of all communication with 1 person, across chat, email and more. This is great for personal usage. Usually I do want to pick up where I left off. Skype offers a massively cut down version of this that I use all the time.
However this has strategic implications for them. Before thinking through those you have to have a view on the source of their competitive advantage and defensible position, is it (a) proprietary culture (product development capabilities) allowing them to release better products and features than anyone else, or (b) the network effects associated with owning your social graph (the usefulness is a function of the other users, as such new networks can’t launch)? I believe it was a, now the high valuations are based on b.
With this new feature you’ll be able to communicate more freely with friends outside facebook. Further, with IMAP and jabber integration you’ll be able to communicate outside facebook.com (i.e. without seeing the ads). You can do that already with wall posts (e.g. tweetdeck). If you think of facebook as the location to communicate with friends (rather than post static information) then they’ve released their grip on that.
Now lets fast forwards, and imagine 20 other cool products (including google) allowing a website and other apps to socialize. They can now interface with most of facebook. Users with facebook accounts (to store their social graph only) can use whatever tool they want (no value to FB). Users without facebook accounts can still interact with facebook users (although can’t see all of the relevant content).
Users will be more likely (than prior to releasing this product) to choose the interface/product that suits them (rather than the one their friends are on). Not great for them.
But then again, they want to ‘connect the world’, not make money, right?
1 Comment | Uncategorized | Permalink
Posted by mhookey
A week or so back mint quietly launched data.mint.com … to provide depersonalized data on shopping trends – E.g. average purchase amounts at tiffany – scraped from mint user accounts.
Interesting data to browse … some commercial questions :
1. I assume they’ve been (at least trying to) resell this data to retailers for a while … why give it away? There are some folks (including the banks) in the business of reselling credit card transaction histories for this purpose that must be finding it tough to compete against this free offer. All I can assume is that they feel that as a benchmarking tool the data will incent new subscribers to sign up to mint (and thus produce some lead gen revenue). However it may also create fear about data privacy.
2. Perhaps they may also attempt to develop an ecosystem by exposing APIs on this data. See an interesting post here : Mint Data Offers a Glimpse Into the Future — and It Is Very Good. (although they could have done this without the public service). How comfortable are users with sharing this type of data with other users (indirectly via benchmarking)?
3. Is it sufficiently depersonalized to protect user data privacy? How many purchases are there each month at Kroger in Carolina Peuro Rico by mint users? Not many I’d guess. This is a more general question – many legal frameworks consider depersonalization to be a binary state – i.e. data with Name/Address/etc is treated one way, data with these columns stripped another. However through fuzzy matching with more dimensions often “depersonalized” data can be used (intentionally or otherwise) to identify the individual. That’s fine in some contexts, but it’s ineffective that the norm is to delineate on the basis of the existence of these columns, rather than setting constraints around the potential to identify individuals.
![]()
Leave a Comment » | Uncategorized | Permalink
Posted by mhookey
I’m not sure many folks recognize just how lucrative the numerous “monitor your credit report” services are for the credit bureaus and others. Here’s the typical sequence :
1. Advertising campaign oriented around fear of identify theft or catchy jingle
2. You sign up to view your credit file with the 3 major bureaus (experian, equifax, and transunion), often thinking it’s free (there’s debate about whether they have misleading advertising practises)
3. They put you on to a fee of around $15/month associated with a monitoring service. You could cancel at any time but many don’t.
(This is not to be confused with Annualcreditreport.com – a government mandated free service to get your annual credit report)
Are customers being misled … or do they really value this service at $15/month? If it were the latter, then why not be more transparent about the cost up-front? Take a look at the landing page of each of the bureaus (truecredit.com, freecreditreport.com, and equifax.com) and see how prominent the word “FREE” is. Maybe some people value the service at $15, and some may even get that sort of value if they’re the target of (frequent) identity theft, but I’d guess many just aren’t paying that much attention.
Maybe this is ok if the bureaus have high costs. Eh. Hang on. Isn’t this data they already own? How much does it cost to run a query and send an email again? The marginal cost has to be pretty close to zero; this is pretty much all marginal profit. There are some fixed advertising costs to sign people up for this.
It’s hard to get granular data on the market size, but it might be >$400m/year at a rough swag (Equifax is $149m/year in personal solutions, Experian has ~10m customers in the US & UK, Transunion is privately held). Some of this includes identity theft protection to be sure, so add some large error bars on that.
They are not scams as some sites claims – the sites do outline the fees for a valuable service – however I hope everyone is going in with their eyes open. Actively monitoring and managing your credit report is important – I hope you’re making a conscious choice about the value of that.
Any thoughts?
4 Comments | Uncategorized | Permalink
Posted by mhookey
